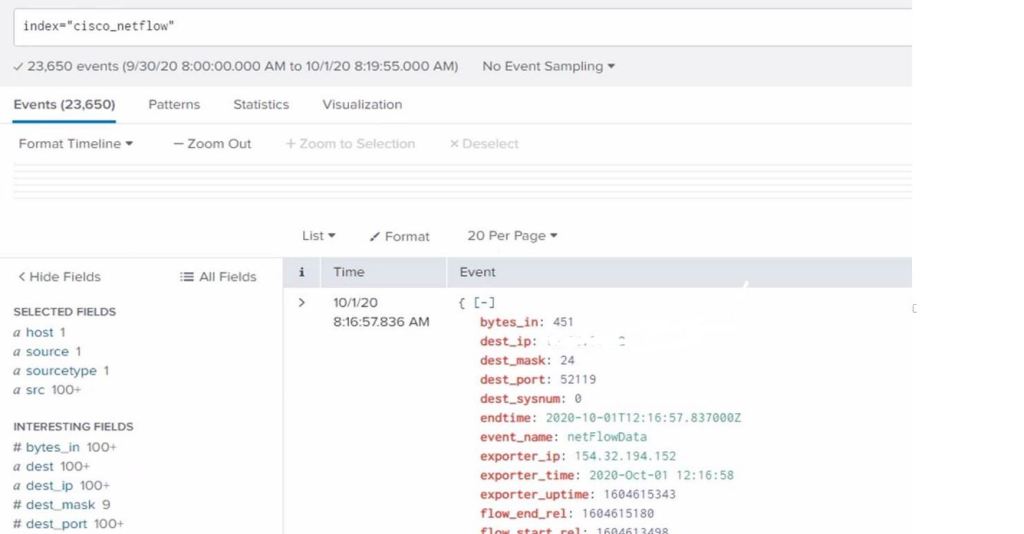
All the details here are for education purposes only, I consider myself an ethical Cyber Security professional working in the data analytics – SIEM space, and this knowledge helps you protect against Cyber Attacks.
But what does that hacker or nation state want? Many reasons, these are some:
- DDoS or DoS Attack (This is to bring down a web site, loss of earnings, hate and competition)
- Data containing sensitive or financial information for reasons such as competition, ransomware, release to public for money, intellectual property, request the organisation or person provide money in exchange of their data should it be encrypted. Credit card details, Strategic secret plans as well.
- Hacktivist – a person who gains unauthorized access to computer files or networks to further social or political end. (Julian Assange was originally a hacker, turned hacktivist, now he’s going to prison and Snowdon is in Russia for the rest of his life, they won’t trust him and look at what Putin’s doing)
- An advanced persistent threat (APT) is a sophisticated, sustained cyberattack in which an intruder establishes an undetected presence in a network to steal sensitive data over a prolonged period.
- Privilege Access – If the hacker has root or Windows Admins privileges, its game over – these are the keys to the kingdom.
- Fun – yes, it’s cool to hack – but this often leads to prison time, or the authorities turn them around to help them. These are just some reasons, but as we have such complex IT environments, the threat surface is large and highly complex and therefore without good Cyber Hygiene we can open ourselves to these Cyber threats.
The hacker’s goal is not to hack every IP address on the internet, that’s plan dumb! They target specific servers that can provide data. If they come across old vulnerable servers, its fair game.
They hack public web sites (Banks) and use Phishing tactics, email links to get into HQ – production network.
They know all this is illegal, so they use various methods to hide and use USB sticks that contain the tools they use for the exploits. This is all in memory and data is refreshed each time its plugged in, TAILS is a good Linux OS for this, and so, it’s cat and mouse game we will always play.
Hackers and Nation States hide behind VPN’s using cloud-based services where they house their attacker systems running Kali Linux and other tools, this way they try and evade detection and prevent leaving footprints. So, their job is also hard and its illegal to hack an organisation and penalties are harsh. They will not use their home, work or places that would revel their location but rather use, cafes, train stations, public places and they try to avoid camera’s as well. (This is in-depth protection)
One thing they really want to do is use a tactic called Reverse Shell, they know Firewall’s block in-coming traffic, but they know outbound is not blocked, as this is required for traffic to flow out, otherwise how would we ever do online business.
If say we manage to get some software or Linux based OS, Rasberry PI onto the network, we can use SSH to create a tunnel between it and another server (Attacker) on the internet.
• Target Raspberry PI Or Server – SSH Port Tunnel 22 (mapped locally to use port 9999:localhost:22)
• Attacker Server on Internet – SSH Ports 9999
You then avoid changes to the password, as this can detected and use a public key pair, this concept, is how one gets access to the network, from inside out (Reverse Shell). From there you can start Nmap and discovery ports and services and continue with the hack.
We do have White Hat hackers, these are good guys, looking for vulnerabilities and advising organisations so they can be fixed. But there are Black Hat Hackers, these are the bad guys, and we need to protect ourselves from them. IP address’s can be traced back, and logs can reveal a lot of information, by collecting this data we can use it to defend and take hackers to court to face justice.
We do have what we call Penetration Test teams, (Red, Blue and Purple Teams, these guys test for vulnerabilities, and these are authorised to hack for this purpose to reporting back so they can be fixed before the hackers identify the vulnerability, without this how do we know how weak our systems are.
So how easy is it hack, well I can run Nmap, identify various services and ports opened for a target online server, then look for vulnerabilities based on the service, run Metasploit, work out the exploit and with a bit of tinkering and reverse shelling and I’m in, but this is Illegal, and you must not do this. All this hacking requires a good deal of knowledge, practise, and time, but it’s not that hard, and there are vast ways of exploiting systems, hackers do not know it all, but they work on target or new emerging technologies, learn them, and then exploit if they can. The more sophisticated hackers are ones that know C++ or other programming languages and can exploit system using their deep software engineering abilities.
Zero Day is the latest tactic – this is a vulnerability not yet patched by the products vendor, imagine this type of vulnerability that lets you into a Linux system as root and the OS Vendor does not know about it, game over!
So, what does these means for us, is we need protection, we use GOOD CYBER HYGENIE, start with Cyber Security Essentials and code of ethics.